Why are we conducting this research?
During pandemic, credit card usage has increased rapidly compared to the year before. Credit cards fraud has been a massive threat for their users. Through the survey and research, some algorithms have been found to decrease the number of fraud Leveraging machine learning and data mining techniques for credit card fraud detection. This research journal aims to investigate and propose the most efficient approach for developing an algorithm that effectively detects credit card fraud.
Why do we conduct research on this topic?
In modern society, particularly in the banking sector, credit cards have become a widely used payment tool. They offer convenience for transactions but require users to pay their outstanding balances monthly. However, the convenience of credit cards is countered by the risk of credit card fraud, including carding, where attackers steal user information to make unauthorized transactions. In 2021, there were 389,737 reported cases of credit card fraud globally, resulting in losses of $32.34 billion. To address this issue, this research explores the effectiveness of various methods, including Random Forest (RF), Logistic Regression (LR), Support Vector Machines (SVM), and Ensemble Methods, to classify and detect potentially fraudulent transactions, ultimately contributing to improved credit card fraud detection models.
What do we do?
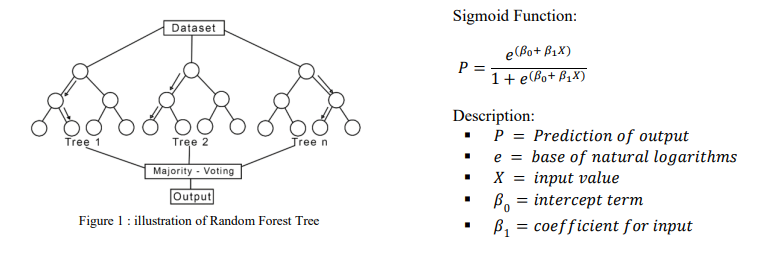
We combined two types of algorithms, SVM (Support Vector Machine) and Logistic Regression, SVM and Random Forest, and Random Forest and Logistic Regression. We used data from Kaggle, which contained one million rows, and split it into 75% for training data and 25% for testing data. We also utilized the scikit-learn library. To combine these two algorithms, we employed Ensemble Learning, a method where we leveraged two different algorithms and conducted a voting process on their results. This concept is similar to Random Forest, but with the distinction that we used different algorithms, making it a heterogeneous ensemble approach.
What were the results?
Based on the experiments conducted, SVM and Random Forest proved to be the most effective combination of algorithms. This combination exhibited the highest accuracy performance, with precision at 100%, recall at 99%, F-Measure at 99%, and an overall accuracy rate of 100%. These results highlight that employing a voting mechanism to create a hybrid model can significantly enhance the accuracy and performance of base classifier models. This approach also opens up possibilities for using different combinations of base classifier methods to create more efficient and faster credit card fraud detection models. Our work demonstrates that combining algorithms, such as SVM and Random Forest, can achieve the highest accuracy. In future studies, we plan to explore the utilization of real-time credit card transaction data for fraud detection. This research aims to enhance the effectiveness of fraud detection algorithms by leveraging ensemble classifier methods and developing more refined algorithms tailored to credit card fraud cases. The ultimate goal is to improve the overall efficiency of credit card fraud detection systems.
Contribution
- Nicholas Christopher
- Feivel Gunawan
- Justin Jefferson